My Dissertation - Week 3

In this issue of 'Dissertation Weekly', my tasks were to implement Google Maps travel API and to get pathfinding working.
Pathfinding
The first step in actually implementing some kind of pathfinding was to get some kind of weight for the edge between each venue/item. To do this I got the latitude and longitude of each venue and then used Pythagoras's Theorem to get the scalar distance between from our origin venue to every other.
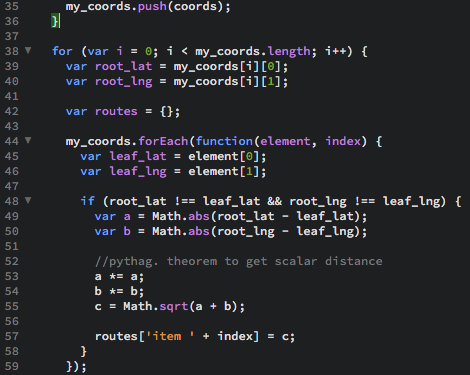
Here is a live code example for anyone wanting it:
Unfortunately I somehow failed to see that using Djikstra's algorithm in a complete graph would pretty much always result in the direct path.
I only worked this out when I had finished implementing Node-Dijkstra... So I began to look up pathfinding algorithms and found: Eulerian Trails and Minimum Spanning Trees.
Eulerian Trails
A Eulerian Trail is a path that visits each node once, no more and no less.
The npm module Eulerian-Trail would be my ideal solution.. if you could add weight to each edge. Unfortunately Eulerian Trails do not take edge weight into account, it literally just creates a route that passes through each node.
Minimum Spanning Trees (MST)
A minimum spanning tree (MST) is a route through a set of nodes that visits all nodes without creating cycles (a loop) and with the minimum weight for the route.
The two most popular algorithms for creating a MST are Kruskal's and Prim's algorithms.
Prim's algorithm
Prim's algorithm starts with a node (root) and looks at all edges from this node to others and finds the smallest among them. You then add the neighbouring node to the route, increasing its size by 1. For N nodes, in N-1 steps every node would be connected to the root node.
Prim's algorithm will only work with a connected graph. A connected graph is a graph where all nodes are connected to one-another by a path.
Kruskal's algorithm
Kruskal's algorithm starts with the smallest global-edge and then iterates choosing the smallest global-edge that does not create a cycle in the current path. For a connected graph this means that for N nodes, in N-1 steps all nodes will be connected
Major differences between Kruskal's and Prim's
-
Prim’s algorithm must be applied to a connected graph while Kruskal’s can be applied to disconnected graphs too.
-
Prim's algorithm initialises with a node, whereas Kruskal's algorithm initialises with an edge.
-
Prim's algorithm chooses the next step in a route by considering all edges connected to it's current node, Kruskal's algorithm instead chooses the smallest edge in the graph that satisfies certain conditions.
Which algorithm will I use?
I decided that I would use Kruskal's algorithm for my project. Prim's algorithm is significantly faster when you've got a really dense graph with many more edges than vertices. Kruskal performs better in typical graphs (such as sparse graphs) because it uses simpler data structures.
The application of MST for my project, is to build a route between some small number of nodes (n < 10). This makes the resulting graph of nodes typically sparse, which means that applying Kruskal's would result in less complex computations.
Complexity is a big factor when developing for Node.js, this is because Node is single-threaded. This means intense computations can block up the thread and stop other pieces of code from being executed.
Why haven't I finished this functionality?
The biggest reason I haven't fully implemented pathfinding on the server-side is because I don't know how I'm going to build and manipulate the resulting array of edges that form the MST.
I think that there will need to be some further research into this, perhaps with a lecturer who is well-versed in such data structures.
Travel information
Using the Google Maps API, specifically the travel information, we can get a variety of travel information between two points.
Research
The following is some research on the Google Maps API, not just things that are helpful to my project specifically but also the oddities that might cause me problems.
Alternatives
A very helpful parameter, if set to true then the Google Maps API will return a few alternative routes.
After some light experimentation I discovered that the supplied alternatives are still for the same mode of transport. Because of this I'm now thinking that I will have to send a request for each mode of transport, every time the server receives a request to the /travel route.
Waypoints
A helpful feature of the Google Maps API that I found was Waypoints.
Waypoints are stop-over points in routes where the user is either walking, cycling or driving. This could be quite important to my project, using this information and generating waypoints for each venue on an itinerary. Doing this you can generate a complete set of travel instructions for the whole itinerary.
Travel Mode
When using the Directions API, which gets.. you guessed it: directions! You can specify your mode of transport, it can be any of the following:
- Driving
- Walking
- Cycling
- Public transport AKA Transit
This parameter defaults to Driving which will be an issue because I don't want my application to assume that people will be driving. The most common form of transport for my user-base will most likely be walking and public transport, pretty much anything but driving.
Region
You can attach a region parameter that will add region bias to the address/location. For instance when I search for "Reading", Google defaults to the Reading in America. With region bias (or adding UK to my address) it will know that I'm pretty unlikely to be looking for Reading in America unless it's actually specified.
Response
The JSON response for a Directions API request is pretty good. It consists of 4 major parts:
- Status code
- Geocoded Waypoints
- Routes
- Available Travel Modes
The Status code is your first port of call when you're checking your response. The status tells you if everything went okay and therefore contains a valid result, or if no responses were found.. along with some other statuses that are pretty unlikely to happen.
The second chunk of the response is also helpful. When you send your origin and destination to the Directions API they are geocoded internally by the service and this can be helpful in diagnosing why you have an unexpected response.
The most important part of the response is the routes. This section contains each route returned by the API, contains a neat summary of the journey and breaks the route down into legs. All helpful stuff!
The final part of the response contains all the available routes' mode of transport. This will be really helpful because I don't want to display an option to get public transport to a venue that doesn't have access to that mode of transport.
Implementing travel data
const googleMapsClient = require('@google/maps').createClient({
key: google_api_key
});
googleMapsClient.directions({
origin: origin_coords,
destination: destination_coords,
alternatives: true
}, function(error, response) {
if (!error) {
// print out only the routes
console.log(response.json.routes);
} else {
console.log('error: ' + error);
}
});
This is a basic implementation of the Directions API, using the node package @google/maps. Note: You will need npm v2.7.0 or newer because this is a scoped package.
You will need to replace google_api_key with your own API key, that you can generate here. Make sure to enable the Directions API on the console, along with any others you want to use!
The origin_coords and destination_coords will also need to be swapped out. For the two corresponding parameters, you can use:
- Addresses
- Sets of latitude and longitude
- Google Places ID
I'm currently using lat and long coordinates for these values, although I am thinking of trying to geocode the coordinates first. If they are successfully geoencoded, I would use the resulting address or Google Places ID.
Testing research
After realising I was unlikely to finish implementing my route plotting logic, I thought it would be good to give my head some space from the problem and do a little of something new. So I began looking into my options for testing and came across lots of options for different parts of my application stack.
Postman testing
I think that using Postman would be great to test my API routes.
It works as most tests do, on the principle that when you do something you have an expected result.
These tests can be packaged into what Postman calls 'Collections' and they are very helpful. I've been using Postman to test and build the API routes, it's helpful to keep them in collections. You can run a collection of tests and then view results, very simple.
Cucumber testing
I think that Cucumber testing is a fantastic choice of testing framework. Cucumber uses Gherkin as it's language for writing tests, Gherkin is great because it acts as documentation and automated tests. It's even better for me as someone relatively unfamiliar with the framework because it tells you the code to write when you're writing the test.
I am planning on using Cucumber to drive the testing of my front-end, this means driving clicks in the application and writing text.